Buongiorno,
sto creando un database access per organizzare i dati ecologici delle mie ricerche sui fiumi. Premetto che è la prima volta che creo un database access. Ho cercato di strutturarlo seguendo le formule normali (le prime tre) ma mi sa che qualche errore c'è per cui anche perchè alcune regole non mi sono chiarissime. Vorrei avere un riscontro sulla struttura del database e su come sono organizzate le singole tabelle. Visto che il database è grandino inizierò a mostrare solo parte delle relazioni in modo che se ci sono errori sistemo quelli prima di procedere oltre.
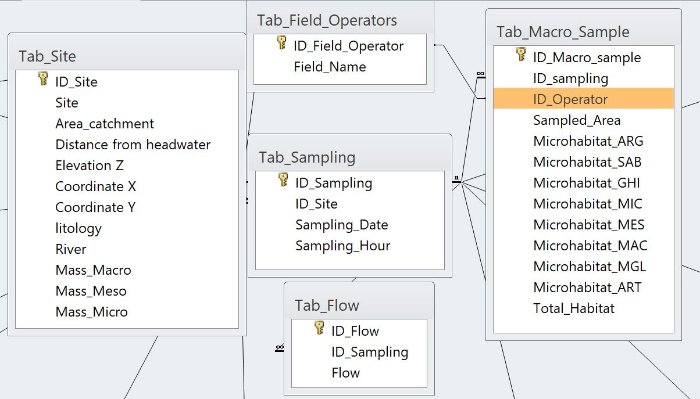
Premessa iniziale: io faccio dei campionamenti in campo in alcuni giorni in alcuni siti in cui raccolgo varie tipologie di dati. (riguardo alla tipologia di substrato, alla portata, alle alghe, agli insetti, alla geologia, alla qualità delle acque....). Ho pensato di strutturare il database così: ogni tabella farà riferimente ad un singolo oggetto (es: portata, oppure substrato, oppure chimica dell'acqua.....) e tutte saranno legate ad una tabella centrale che è quella dei campionamenti (Sampling). La tabella Sampling è legata ad una tabella siti (Site) dove sono contenute informazioni riguardo ai siti di campionamento (coordinate, quota, litologia...).
La tabella Site è pertanto l'unica già compilata. Tutte le altre tabelle verranno riempite man mano attraverso delle maschere di immisione dati.
In particolare per ora ho:
-la tabella centrale (Sampling) con:
ID_Sampling: (la chiave primaria a cui sarà legato tutto, numerazione automatica)
ID_Site: (per legare la tabella Site): numerico
la data: (data) e l'ora (testo)
-la tabella Site con:
ID Site: (numerazione automatica)
Site: il nome del sito (testo)
L'area del bacino che insiste su quel punto (numerico) e la distanza dalla sorgente (numerico)
La cordinata x (numerico), y (numerico) e z (numerico)
il tipo di litologia (testo)
il nome del fiume (testo)
il peso medio dei ciottoli grandi (numerico), dei cittoli medi (numerico), dei ciottoli piccoli (numerico)
-la tabella degli Habitat (Macro_Sample) con:
ID_Macro Sample: numerazione automatica
ID_Sampling: numerico
ID_Operator: numerico
Area_Sampled: (area di campionamento): numerico
e poi una serie di campi (Microhabitat_ARG..) che sono campi numerici che fanno riferimento alla percentuale di area campionata in cui vi è argilla, ghiaia..
ho poi introdotto un campo calcolato: Total_Habitat che è la somma degli habitat sopra citati
-la tabella Field_Operator oltre alla chiave in numerazione automatica contiene il nome (Field_Operator) di chi effettua il campionamento.
-la tabella Flow che oltre alla chiave in numerazione automatica contiene la portata (numerico)
I miei dubbi a questo punto sono:
sto procedendo correttamente? posso avere tabelle (es Tab_Site) che contiene sia campi numerici che di testo? il campo Total_Habitat che è calcolato va bene inserirlo nella stessa tabella o andrebbe meglio farlo in una separata? (che conterrà solo ID_Macro_Sample e Total_Habitat)? se sì, perchè?
Scusate la lunga descrizione, spero si capisca. Grazie a chi saprà darmi un riscontro
Allegati:
 30854_ba10003a78725e984178973fa280f21f.jpg
30854_ba10003a78725e984178973fa280f21f.jpg